

Desde o seu lançamento público 10 anos atrás, o Twitter tem sido usado como uma plataforma de rede social entre amigos, um serviço de mensagens instantâneas para usuários de smartphones e uma ferramenta promocional para corporações e políticos.
Mas também tem sido uma fonte inestimável de dados para pesquisadores e cientistas - como eu - que querem estudar como os seres humanos se sentem e funcionam dentro de sistemas sociais complexos.
Analisando os tweets, pudemos observar e coletar dados sobre as interações sociais de milhões de pessoas "em estado selvagem", fora de experimentos controlados em laboratório.
Isso nos permitiu desenvolver ferramentas para monitorar emoções coletivas de grandes populações, encontre o lugares mais felizes nos Estados Unidos e muito mais.
Então, como exatamente o Twitter se tornou um recurso único para os cientistas sociais computacionais? E o que nos permitiu descobrir?

O maior presente do Twitter para pesquisadores
Em julho 15, 2006, Twittr (como era então conhecido) publicamente lançado como um “serviço móvel que ajuda grupos de amigos a enviar pensamentos aleatórios com o SMS”. A capacidade de enviar textos de grupo de caracteres 140 livres levou muitos dos que adotaram precocemente (inclusive eu) a usar a plataforma.
Com o tempo, o número de usuários explodiu: de 20 milhões em 2009 para 200 milhões em 2012 e 310 milhões hoje. Em vez de se comunicar diretamente com os amigos, os usuários simplesmente diziam aos seus seguidores como eles se sentiam, respondiam às notícias de maneira positiva ou negativa, ou faziam piadas.
Para os pesquisadores, o maior presente do Twitter tem sido o fornecimento de grandes quantidades de dados abertos. O Twitter foi uma das primeiras grandes redes sociais a fornecer amostras de dados por meio de APIs (Application Programming Interfaces), que permitem aos pesquisadores consultar o Twitter para tipos específicos de tweets (por exemplo, tweets que contêm certas palavras), bem como informações sobre usuários. .
Isso levou a uma explosão de projetos de pesquisa que exploram esses dados. Hoje, uma pesquisa do Google no Google para o "Twitter" produz seis milhões de acessos, em comparação com cinco milhões para o "Facebook". A diferença é especialmente impressionante, já que o Facebook tem aproximadamente cinco vezes mais usuários que o Twitter (e é dois anos mais velho).
A generosa política de dados do Twitter, sem dúvida, levou a uma excelente publicidade gratuita para a empresa, já que estudos científicos interessantes foram captados pela grande mídia.
Estudar felicidade e saúde
Com os dados do censo tradicional lentos e caros de coletar, os feeds de dados abertos, como o Twitter, têm o potencial de fornecer uma janela em tempo real para ver as mudanças em grandes populações.
Universidade de Vermont Laboratório de Histórias Computacionais foi fundada em 2006 e estuda problemas em matemática aplicada, sociologia e física. Desde o 2008, o Story Lab coletou bilhões de tweets por meio do feed "Gardenhose" do Twitter, uma API que transmite uma amostra aleatória de 10 por cento de todos os tweets públicos em tempo real.
Passei três anos no Laboratório de História da Computação e tive a sorte de fazer parte de muitos estudos interessantes usando esses dados. Por exemplo, desenvolvemos um hedonômetro que mede a felicidade da Twittersfera em tempo real. Ao focar nos tweets geolocalizados enviados por smartphones, conseguimos mapa, os lugares mais felizes nos Estados Unidos. Talvez sem surpresa, encontramos Havaí para ser o estado mais feliz e vitícola Napa a cidade mais feliz para 2013.
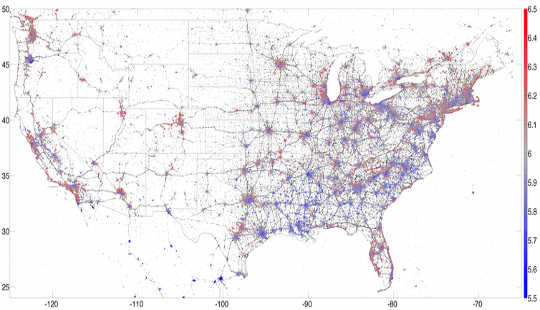 Um mapa de 13 milhões geolocalizou os tweets americanos de 2013, coloridos pela felicidade, com o vermelho indicando felicidade e o azul indicando tristeza. PLoS ONEAutor fornecido.Esses estudos tiveram aplicações mais profundas: Correlacionar o uso de palavras no Twitter com dados demográficos nos ajudou a entender os padrões socioeconômicos subjacentes nas cidades. Por exemplo, poderíamos vincular o uso de palavras a fatores de saúde como a obesidade, então construímos um lexicocalorímetro para medir o “conteúdo calórico” dos posts nas redes sociais. Os tweets de uma determinada região que mencionavam alimentos altamente calóricos aumentavam o “conteúdo calórico” daquela região, enquanto os tweets que mencionavam atividades físicas diminuíam nossa métrica. Descobrimos que esta medida simples correlaciona-se com outras métricas de saúde e bem-estar. Em outras palavras, os tweets foram capazes de nos dar um instantâneo, em um momento específico, da saúde geral de uma cidade ou região.
Um mapa de 13 milhões geolocalizou os tweets americanos de 2013, coloridos pela felicidade, com o vermelho indicando felicidade e o azul indicando tristeza. PLoS ONEAutor fornecido.Esses estudos tiveram aplicações mais profundas: Correlacionar o uso de palavras no Twitter com dados demográficos nos ajudou a entender os padrões socioeconômicos subjacentes nas cidades. Por exemplo, poderíamos vincular o uso de palavras a fatores de saúde como a obesidade, então construímos um lexicocalorímetro para medir o “conteúdo calórico” dos posts nas redes sociais. Os tweets de uma determinada região que mencionavam alimentos altamente calóricos aumentavam o “conteúdo calórico” daquela região, enquanto os tweets que mencionavam atividades físicas diminuíam nossa métrica. Descobrimos que esta medida simples correlaciona-se com outras métricas de saúde e bem-estar. Em outras palavras, os tweets foram capazes de nos dar um instantâneo, em um momento específico, da saúde geral de uma cidade ou região.
Usando a riqueza dos dados do Twitter, também pudemos veja os padrões de movimento diários das pessoas em detalhes sem precedentes. A compreensão dos padrões de mobilidade humana, por sua vez, tem a capacidade de transformar a modelagem de doenças, abrindo o novo campo de epidemiologia digital.
Para outros estudos, analisamos se os viajantes expressam maior felicidade no Twitter do que aqueles que ficam em casa (responda: eles fazem) e se indivíduos felizes tendem a ficar juntos em uma rede social (novamente, eles fazem). De fato, positividade parece ser cozido na própria linguagem, no sentido de que temos mais palavras positivas do que palavras negativas. Este não foi o caso apenas no Twitter, mas em uma variedade de mídias diferentes (por exemplo, livros, filmes e jornais) e idiomas.
Esses estudos - e milhares de outros como eles de todo o mundo - só foram possíveis graças ao Twitter.
Os próximos 10 anos
Então, o que podemos esperar aprender com o Twitter nos próximos anos da 10?
Alguns dos trabalhos mais interessantes atualmente envolvem a conexão de dados de mídia social com modelos matemáticos para prever fenômenos no nível da população, como surtos de doenças. Pesquisadores já tiveram algum sucesso no aumento de modelos de doenças com dados do Twitter para prever a gripe, notadamente FluOutlook plataforma desenvolvida pela Northeastern University e pelo Institute for Scientific Interchange.
Ainda assim, vários desafios permanecem. Os dados de mídia social sofrem de uma "relação sinal-ruído" muito baixa. Em outras palavras, os tweets que são relevantes para um estudo em particular são frequentemente abafados pelo "ruído" irrelevante.
Portanto, devemos estar continuamente conscientes do que foi apelidado de “hubris de big data”Ao desenvolver novos métodos e não ter excesso de confiança em nossos resultados. Conectado a isso deve estar o objetivo de produzir previsões interpretáveis de “caixa de vidro” a partir desses dados (em oposição às previsões de “caixa preta”, nas quais o algoritmo está oculto ou não está claro).
Os dados de mídia social são frequentemente (bastante) criticados por serem pequenos, amostra não representativa da população em geral. Um dos maiores desafios para os pesquisadores é descobrir como explicar esses dados distorcidos em modelos estatísticos. Enquanto mais pessoas estão usando mídias sociais a cada ano, devemos continuar tentando entender os vieses nesses dados. Por exemplo, os dados ainda tendem a sobre-representar os indivíduos mais jovens em detrimento das populações mais velhas.
Somente depois de desenvolver melhores métodos de correção de viés, os pesquisadores poderão fazer previsões totalmente confiáveis dos tweets.
Sobre o autor
Lewis Mitchell, professor de matemática aplicada, Universidade de Adelaide
Este artigo foi originalmente publicado em A Conversação. Leia o artigo original.
Livros relacionados
at InnerSelf Market e Amazon




















